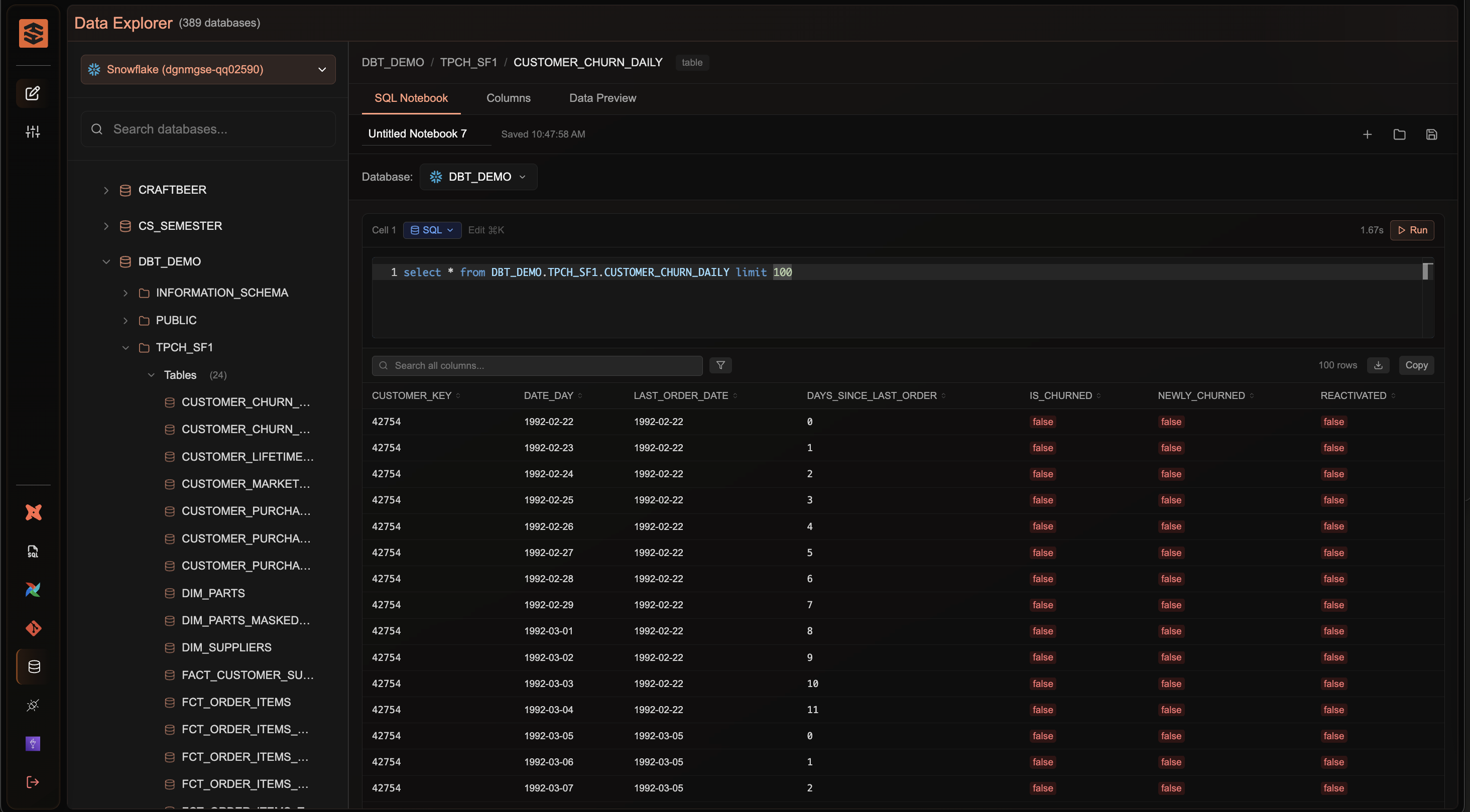
TensorStax uses autonomous AI to not just visualize or monitor pipelines, but to actively build, optimize, and maintain them. It integrates directly with your stack (like dbt, Spark or Airflow) and generates production-ready pipelines, with customization and version control out of the box.
TensorStax is also fully aware of your schemas, infrastructure and has context on how how you prefer to structure your pipelines.










.avif)



.avif)

