
Thinkquel represents a significant leap in database query generation, combining state-of-the-art synthetic data techniques with a novel training approach specifically designed for the unique challenges of text-to-SQL and text-to-dbt tasks.
.png)
Thinkquel tackles text-to-dbt generation through two primary innovations: a rigorous synthetic data pipeline and a span-aware reinforcement learning objective that aligns learning with both the reasoning-based and the execution-based rewards.
Creating high-quality training data for database transformations is expensive and time-consuming. Our TensorStax-SQL (TS-SQL) pipeline solves this by programmatically generating millions of diverse dbt models, then intelligently refining and curating them with execution validation and semantic evaluation.

Unlike template-based methods, TS-SQL explores a wider complexity space through systematic variation of structural parameters, CTEs, transformations, set operations, conditional aggregates, and subqueries, across staging, intermediate, mart, and report model types. Each generated model executes against real databases, ensuring syntactic validity. We then refine these models using Qwen3-Coder-480B to produce meaningful identifiers and enhance logic, before generating diverse natural language questions that match realistic user intent.
Quality control is rigorous: Claude Sonnet 4 evaluates each question-model pair on clarity, semantic alignment, efficiency, and technical correctness, with only pairs scoring 9/10 or higher making the final cut.
We target dbt rather than raw SQL because portability matters. While raw SQL is powerful, it lacks cross-warehouse compatibility and offers no built-in support for testing, documentation, or dependency management. dbt addresses these limitations by acting as a modern abstraction layer over SQL, handling cross-dialect compilation, enabling modular and reusable code, and integrating natively with version control and CI/CD workflows.
By generating dbt models, Thinkquel produces outputs that are not just correct, but robust, maintainable, and immediately deployable in modern data stacks.
Standard reinforcement learning approaches struggle with text-to-dbt because the strongest supervision signals, execution success and result matching, operate at the sequence level, while traditional methods weigh every token individually. This mismatch creates unstable optimization and limited portability. However, the GSPO method, which replaces GRPO’s token-wise correction with a length-normalized sequence ratio, can underuse local, token-level signals (e.g., formatting or schema-linking rewards).
Token–Sequence GRPO (TS–GRPO) solves this by routing different types of signals to different spans of the model's output:
This span-aware routing, together with separate asymmetric gradient clips for different spans to keep SQL conservative and planning explorative, reduces variance, prevents cross-span credit leakage, and better matches the error surface of text-to-dbt generation. Our training also incorporates concise, structured planning before code generation, forcing the model to explicitly identify necessary tables and columns, define sub-problems, and outline assembly logic before committing to low-level syntax.
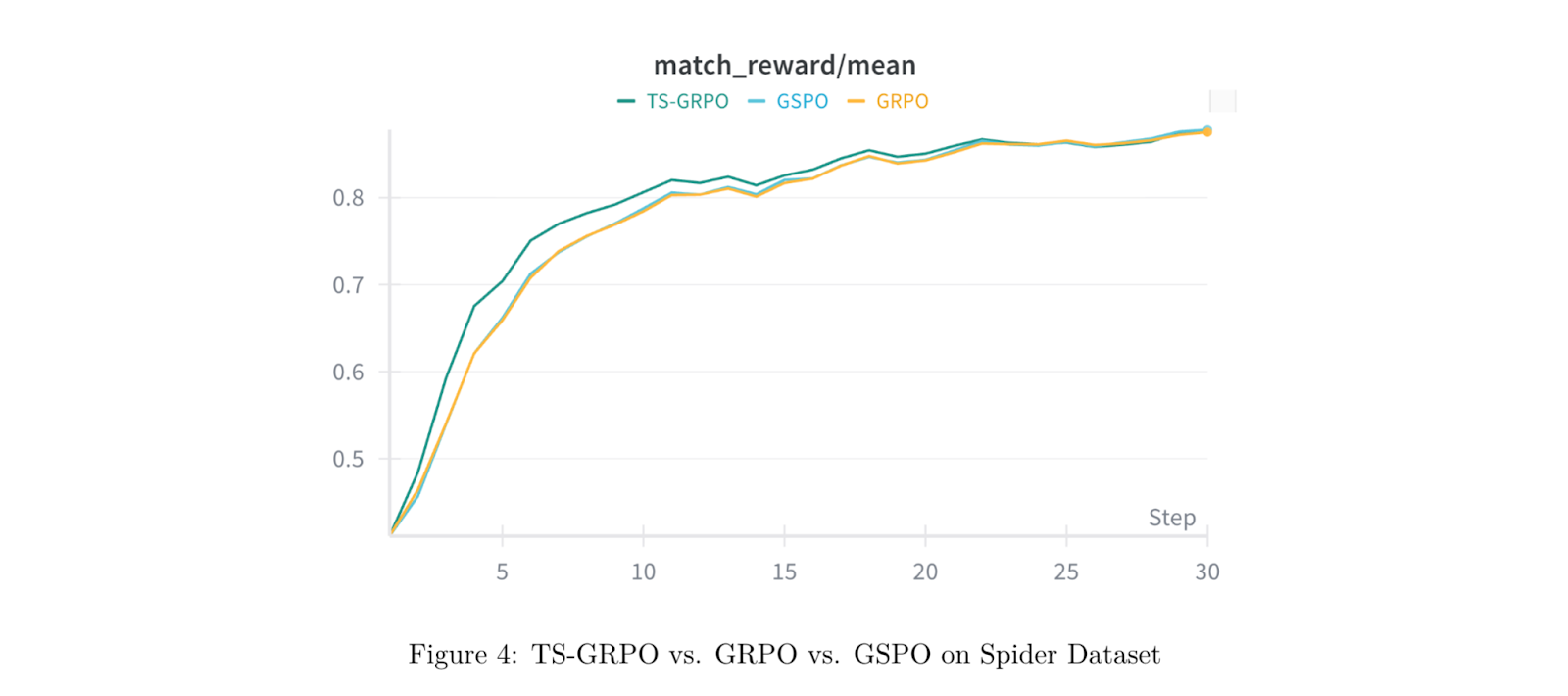
Across text-to-SQL and text-to-dbt benchmarks, TS–GRPO delivers faster, more stable training than existing methods:
The two-stage supervised fine-tuning curriculum with explicit planning provides most of the jump from base capability to robust dbt generation, while TS–GRPO tightens execution-aligned optimization to close the remaining gap.
We're evolving Thinkquel from a single-shot generator into an interactive agent that can query schemas, validate intermediate results, and self-correct during generation through multi-turn RL with tool-use.
The full research paper, Thinkquel: A Model Dedicated to Text-to-dbt Using Synthetic Data and a Span-Aware Objective, is available now. It details the TS-SQL pipeline, TS-GRPO objective, and experimental results. -> https://arxiv.org/abs/2510.00186
Anni Li, Aria Attar, Paul Dong
.avif)








.avif)

